 ChatGPT Pro 俱乐部
ChatGPT Pro 俱乐部
最近老铁在使用claude code的时候发现了一个非常非常致命的问题,那就是总感觉claude code 200k的上下文不顶用,每次在一个项目让claude code执行操作三四次的时候就会发现左下角显示上下文不够的提示,然后就得使用/clear 或者/compact 但是只要上下文压缩过了,那么之前的细节很多其实claude code就已经不知道了,最明显的表现就是之前已经读取过的代码又需要重新读取一次,不仅浪费了token而且还花费了多余的时间。还有就是claude code每次中断之后之前保存的记录可能就会消失虽然可以使用claude -c或者claude -r恢复记录但是第一次的时候还是会将所有的代码通读一边,上面的痛点依然存在。
基于上述的问题我发现了一个可以自动的让claude code能够将对话的记录包括代码的结构,功能等等所有内容全部记住的mcp工具 —— Graphiti MCP Server
Graphiti 是一个时间感知知识图谱框架,与传统的 RAG (检索增强生成) 不同,它能够:
- 持续集成用户交互、结构化和非结构化数据
- 支持增量数据更新
- 进行精确的历史查询
- 无需完全重新计算图谱
在配置之前需要准备如下的东西:
1,Neo4j
http://localhost:7474/browser/preview/
2,Docker: 最新版本
3,Docker Compose: 最新版本
4,uv: Python包管理器(推荐)
下面我手把手教大家如何配置:
# 安装uv(推荐)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 或使用pip
pip install uv
git clone https://github.com/getzep/graphiti.git
cd graphiti/mcp_server
uv sync
cp .env.example .env
# 配置Neo4j
## 下载
https://neo4j.com/download/
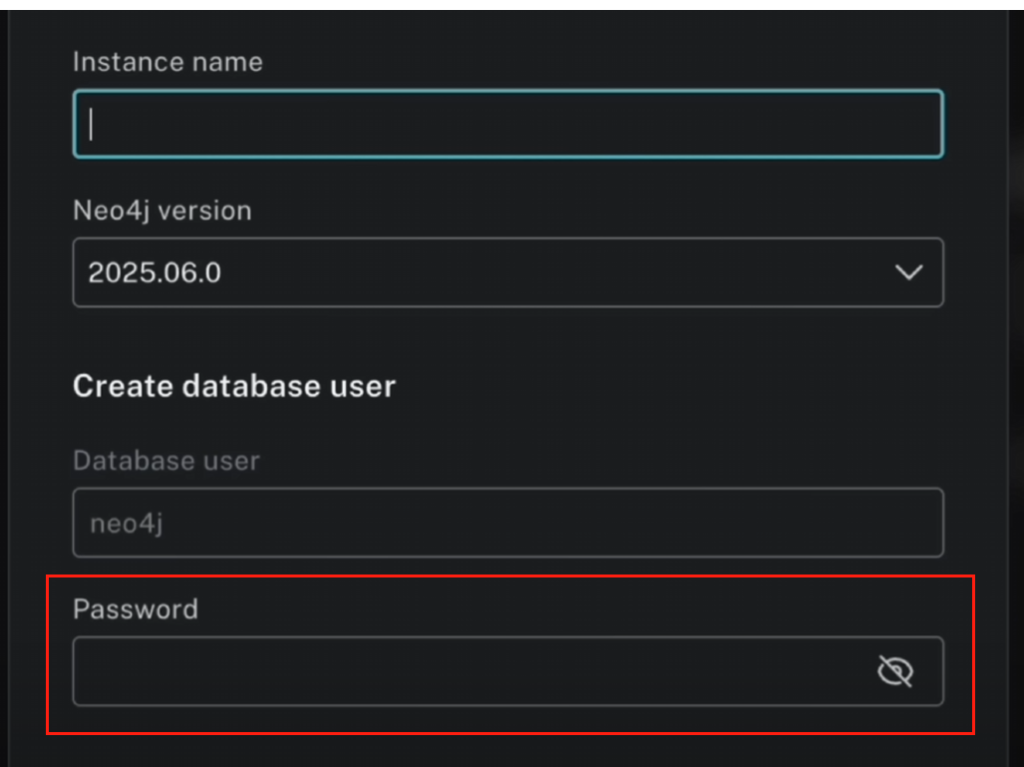
# Instance name
graphiti-db
# Database user
neo4j
# Password
grop12345 (下载Neo4j的时候会让你配置密码,这个你配置的密码就替换成这个,详情看下面的第二张图)
# 使用pwd命令查看当前路径
pwd
# 使用which uv命令查看uv所在路径
which uv配置完成之后就可以直接在claude code MCP中配置如下的内容:
直接粘贴复制即可(注意把command中的路径修改成自己本机电脑的)
claude mcp add-json graphiti-memory '{
"type": "stdio",
"command": "/Users/charlesqin/.local/bin/uv",
"args": [
"run",
"--isolated",
"--directory",
"/Users/charlesqin/graphiti/mcp_server",
"--project",
".",
"graphiti_mcp_server.py",
"--transport",
"stdio"
],
"env": {
"NEO4J_URI": "bolt://localhost:7687",
"NEO4J_USER": "neo4j",
"NEO4J_PASSWORD": "graphiti123!",
"OPENAI_API_KEY": "sk-proj--xxxxxxxx", 这里需要配置OpenAI的api key
"MODEL_NAME": "gpt-4.1-mini"
}
}'下面我将贴几张图:
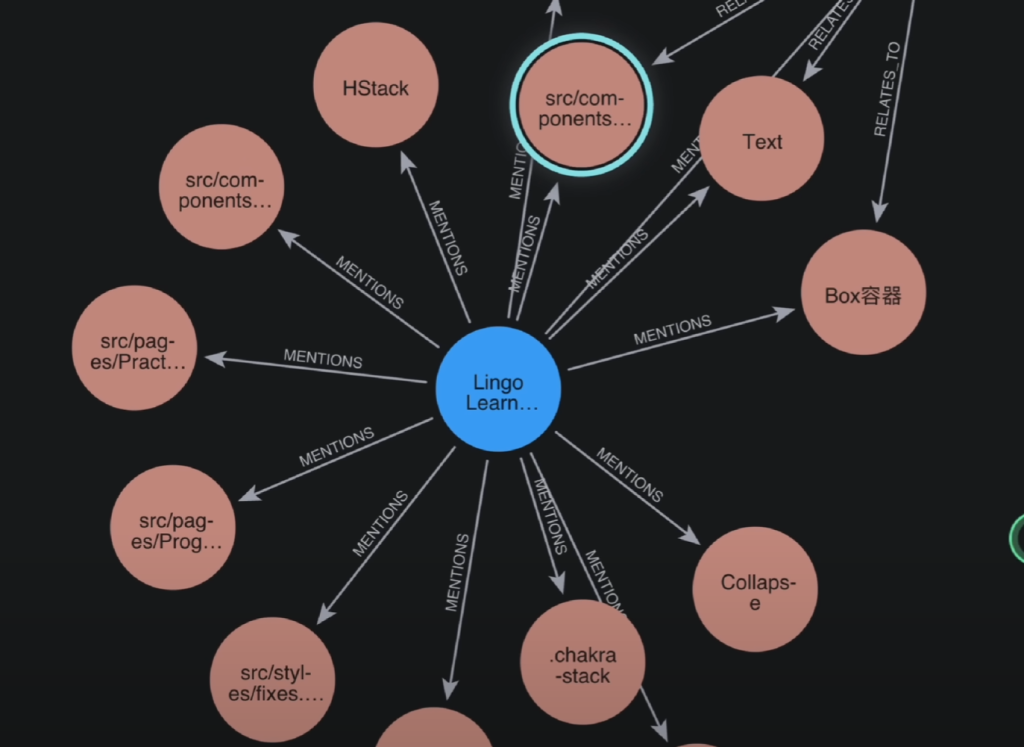
这个是使用Neo4j工具的保存的你项目的知识图谱如下:
下面是Neo4j的创建界面,用户名不用修改密码的话使用自己能记得住的上面之前的配置的时候需要用上:
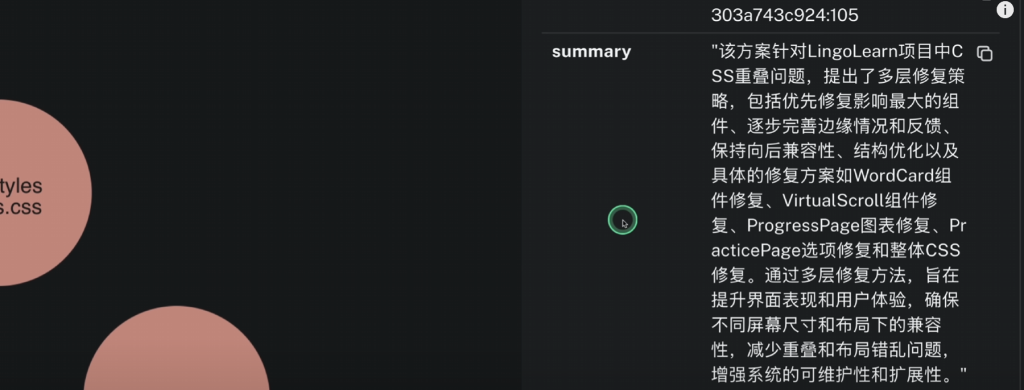
点击每一个知识点的时候就会有详细的记录信息如下:
大家在配置的过程中有任何问题可以直接访问:https://github.com/getzep/graphiti 这个就是Graphi的官方的githup仓库